Downloading a firmware image and opening it up for the first time can be a great motivator - a list of bytes that somewhere hides executable code, just waiting to be analysed. Maybe you'll be the first person to have done so. Maybe you're the thousandth but you're up for a challenge.
I'm sure there's two types of people - those who lose all hope when binwalk doesn't spit out a single useful signature match, and those whose motivation to uncover the hidden secrets skyrockets. I'm not sure where I stand; it takes me a couple hours staring aimlessly at a hex editor, head-in-hands, for the motivation to completely fizzle.
So with a firmware image acquired, I turned to binwalk and xxd for some light. Light that neither tool decided to shed onto the structure of the image.
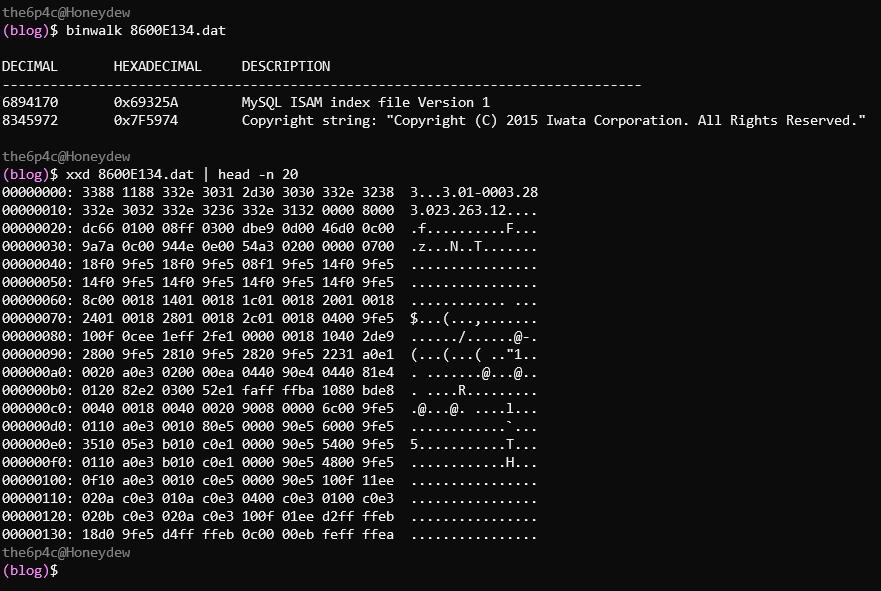
That's alright - it doesn't take much to fool binwalk into not displaying any matches. Let's employ another fun trick: converting our binary file into a PGM image (thanks scanlime) to get an idea of how the file is structured. The 8600E134.dat file is 10,383,159 bytes long - just a few bytes more than a 512 pixel wide, 20,000 pixel tall, 1-byte-per-pixel image. That corresponds to a PGM header of P5 512 20000 255\n which we'll prepend to the binary (click here for a bigger, not truncated version).
{kind=link}

Looks like our file is actually a number of separate images, separated by large swaths of white 0xFF bytes. Not much use to us just yet.
Can strings give us a lead? If the file was simply a raw flash image that the processor loads and runs from 0, we'd expect to see the application's strings just sitting around in the binary. In this case since our binary starts with a very ASCII-looking string, there might be a header in the way, but that won't change the presence of raw strings further on in the file.
Unsurprisingly, running strings 8600E134.dat > 8600E134.dat.strings produces a 186,938 line file. Opening the listing in a text editor reveals something interesting however: not a single string of decent length was in one piece. Did we break strings, or is something else going on?
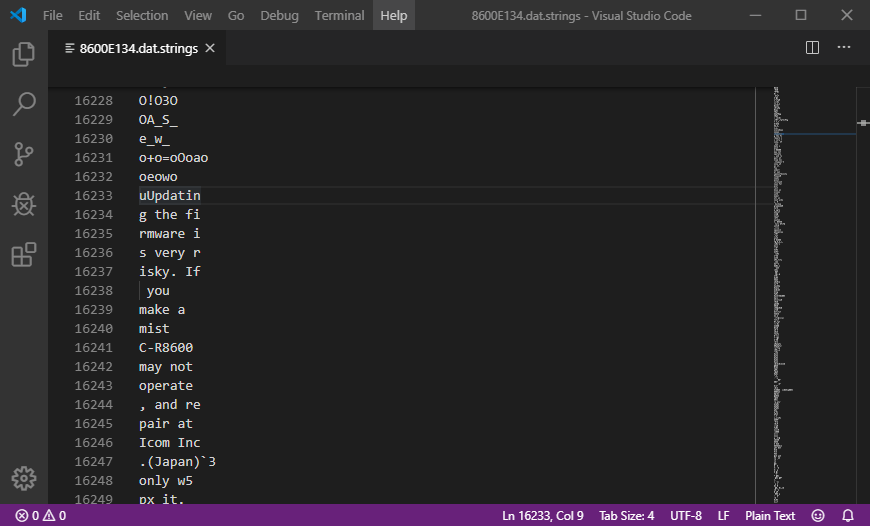
In a hex editor, it's clear that strings knew what it was doing. All of these strings are... odd. We've got enough of the string to work out what it once was, and the manual shows us what the original is. My "revelation" here may have already been spoiled for you, but see if you can spot what I eventually did.
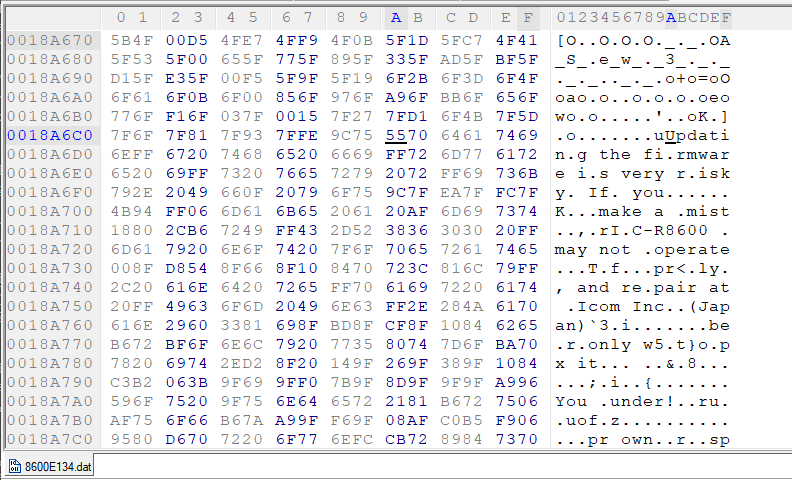

For a while, the entirely missing segments of the string baffled me. Where's the end of "mistake"? Where did the "ake" go? But with time, the revelation came - not more than 10 characters earlier did the string "ake" also occur. The "oper" of "properly"? Already there, at the start of "operate".
We've got some kind of compression here.
Compression
Compression formats all operate on a shared principle - during compression, repetitive data can be replaced with some kind of marker which signals to the decompressor to stop, write out a sequence of bytes from some known source, and continue. Non-repetitive, or high entropy data can simply be stored as-is: no space savings can be found by replacing it with marker values, as at length it's probably unique within the file.
Some compression formats utilise an explicit dictionary to perform this task - either running through the file before compression begins to find an optimal list of such repetitive byte sequences, or by progressively building a dictionary as compression is performed. In either case, the algorithm's marker values are simply a command to the decompressor to "grab the dictionary string at index 0x13," (for example) "and write it to the output".
Markedly different are compression algorithms which utilise a sliding window. Rather than creating an explicit dictionary which maps indices to byte strings, marker values encode an offset from the current file position and a length: when a marker is encountered while decompressing, the decompressor seeks backwards by the offset value and copies the specified number of bytes from the already decompressed data into the output file.
The missing repetitive values we see in our data are short, and when data is missing the block to be repeated occurs very close to the gap. Sounds like a sliding window algorithm, right? An explicit dictionary format probably wouldn't find adding a string as short as "ake" or "oper" to its dictionary as a smart (i.e. file-size reducing) move.
Let's run with this hunch.
Our format
One thing you may have noticed in the hex view of the image was that every string of 8 literal characters (i.e. not compressed, and should be written directly to the decompressed file) was prefixed by an 0xFF byte.
# ^ tons of bytes removed
7F 6F 7F 81 7F 93 7F FE 9C 75 55 70 64 61 74 69 6E # not sure what's going on here...
FF 67 20 74 68 65 20 66 69 # "g the fi"
FF 72 6D 77 61 72 65 20 69 # "rmware i"
FF 73 20 76 65 72 79 20 72 # "s very r"
FF 69 73 6B 79 2E 20 49 66 # "isky. If"
0F 20 79 6F 75 9C 7F EA 7F FC 7F 4B 94 FF 06 6D 61 6B 65 # ...or here
# v tons of bytes removed
We can't just go searching through the file for 0xFF bytes, since when we don't know the entire plaintext we can't be 100% sure that the 0xFF byte we found isn't actually meant to end up in the plaintext. We can be 99.99% sure that in this case, our 0xFF byte is actually some kind of "8 literal bytes follow" marker, because we know the plaintext and no other interpretation would really make sense. We almost fall "out of sync" as soon as we hit a non-0xFF byte after a 0xFF [8 literal byte] sequence, since we can't be sure what that next byte tells the decompressor to do. If we continue to go at this alone, without many, many hours of reverse engineering, we've kinda hit a dead end.
Final Fantasy VII, aka great LZSS documentation
I can't tell you how exactly I worked out what compression algorithm the firmware image used. To be honest, I think I stumbled upon some documentation and the Wikipedia article much earlier in the RE effort than I remember (after searching something like "0xFF 8 literal bytes"), but I wrote it off pretty quickly for some reason. I think it was partially due to misinterpreting the docs, but that's in the past now. Who knows.
Turns out our compression is LZSS, and our win comes in the form of documentation for the Final Fantasy VII data file format. Combined with Wikipedia's outline of LZ77 (which utilises similar principles, and was helpful in understanding how the LZSS format operates), we've got enough to write our own decompressor.
I'll "summarise" the LZSS format here.
An LZSS compressed file is comprised of a header (4 bytes - simply the decompressed length of the file stored in little endian), followed by a series of blocks.
Blocks
Each block begins with a control byte, which dictates how the bytes which follow the control byte are to be interpreted. A control byte is always followed by 8 pieces of data (note: not necessarily 8 bytes), which may each be either a literal byte (1 byte long), or a reference (2 bytes long).
Each bit of the control byte defines what pieces of data are present after the control byte, with a 0 bit indicating a reference and a 1 bit indicating a literal. Bit 0, the least-significant bit, defines the piece of data which immediately follows the control byte. Bit 7, the most-significant bit, defines the piece of data which immediately precedes the next control byte.
As each byte of the decompressed file is calculated, it is written to a circular buffer of length 4096 bytes. The first byte of the decompressed file is placed at index 0xFEE of the buffer, and the index incremented by one byte. Subsequent bytes are written at the current index, the index incremented, and the index wrapped around to 0 if it exceeds 4095 (the last position in the buffer).
The buffer is initialised to all zeros.
| Control byte | Data |
|---|---|
0xFF = 0b1111_1111 |
8 literals |
0xFE = 0b1111_1110 |
1 reference, followed by 7 literals |
0x7F = 0b0111_1111 |
7 literals, followed by 1 reference |
0xE3 = 0b1110_0011 |
2 literals, followed by 3 references, followed by 3 literals |
Literals
Literals are one byte in length, and as the name suggests - should be copied into the output file untouched.
References
A reference is two bytes in length, and encodes both a length and offset. The offset is not relative to the current index, i.e. an index of 0x210 is 0x210 bytes from index 0 of the circular buffer. When encountered, the requested number of bytes should be copied from the circular buffer and into the output file, beginning at the requested offset into the buffer.
| Byte | p |
p+1 |
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| Value | Offset (low byte) | Offset (high nibble) | Length (stored as length - 3) |
|||||||||||||
Note: offset = [high nibble] << 8 | [low byte].
The length of a reference is stored minus 3 as any reference which pulls in less than 3 bytes would take up less space if written as a pair of one or two literals. The data referenced by a length-offset pair can include data which has not yet been written to the file (i.e. offset 2, length 4) as - operating one byte at a time - the bytes which appeared to not yet exist are written before they are needed (Wikipedia explains this better).
Decompression
Before we can think about decompression, we must isolate the compressed block from the firmware. Recalling the 0xFF-delimited blocky structure of the image we saw earlier, if we work backwards from where we found our strings above, we can find the first couple non-0xFF bytes of the block. They're more than likely the start of the block.
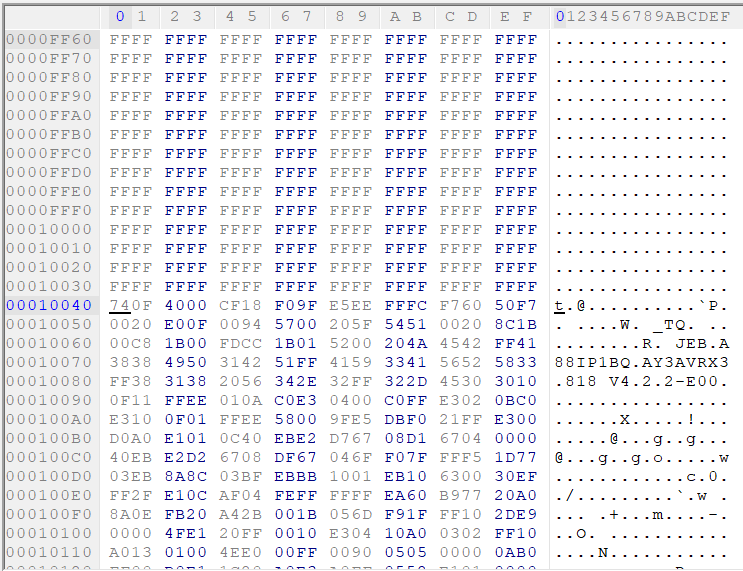
The end of the block isn't as easy - we've got to be mindful that we're not 100% sure where the block ends (since the decompressed section could be end-padded with 0xFF which would look just like our filler data!) and so it's safer that we just chop the extra front-matter off instead. Our compression format stores the decompressed length, so we're unlikely to accidentally start attempting to decompress data that isn't actually compressed.
We'll copy from the offset 0x10040, where the compressed data starts, to the end of the file. That becomes compressed.bin.
With all this information about the format and our compressed data, we can implement a quick Python script to do our decompression.
We have some known plaintext, so let's go looking:
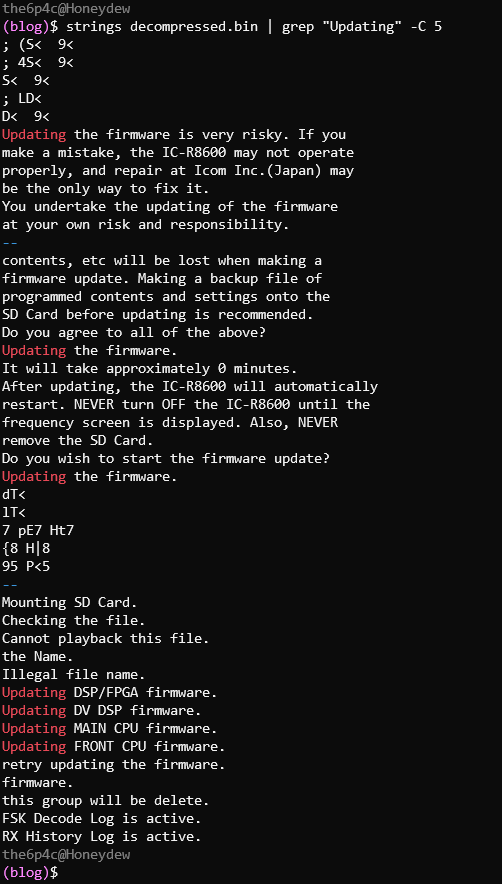
Much more like it :)
A retrospective
After I'd continued the RE process it turns out that this firmware image is (as suspected) simply written into on-board flash and executed from 0 (skipping 0x40 bytes of header). The firmware's first step is to load a second stage from flash into RAM, which then loads the actual application into RAM by decompressing it with LZSS 🤦♀️
My first step could have been doing the research to find that the device runs on an ARM Cortex-A9, loading the image into a disassembler, seeing some plausible code and following the loading stages... but then, instead of trying to find a mystery compression algorithm I'd probably be staring at a bunch of machine code, trying to reverse engineer an algorithm I'd have assumed was proprietary or just obfuscation. It's easy to say in hindsight that this would have been a better route and "I totally would have realised it was a common algorithm!" but I don't think that's true. The only reason I was able to locate the decompression routine in the second stage was because I knew to look for the 0xFEE constant - information I wouldn't have known if I'd started from code.
Lessons learned, if nothing else.